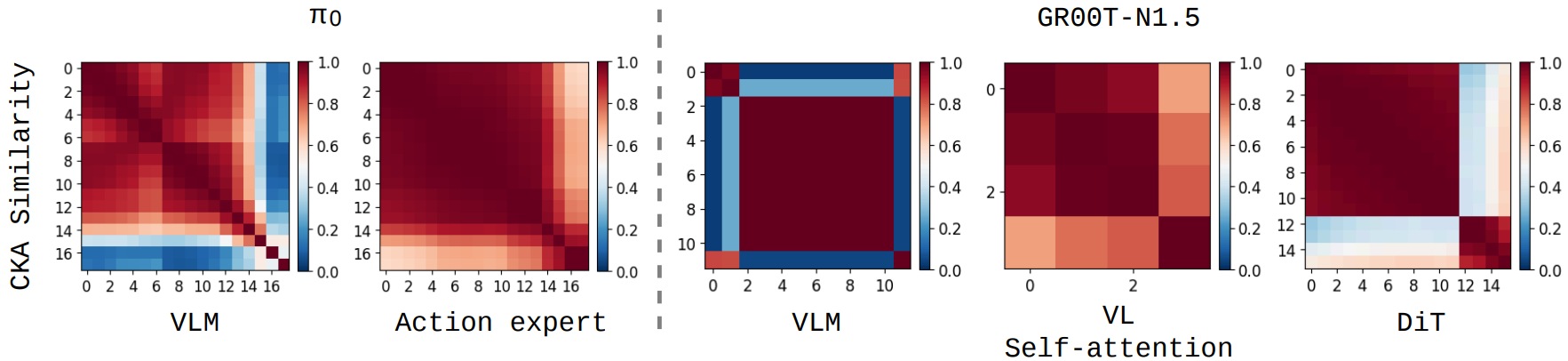
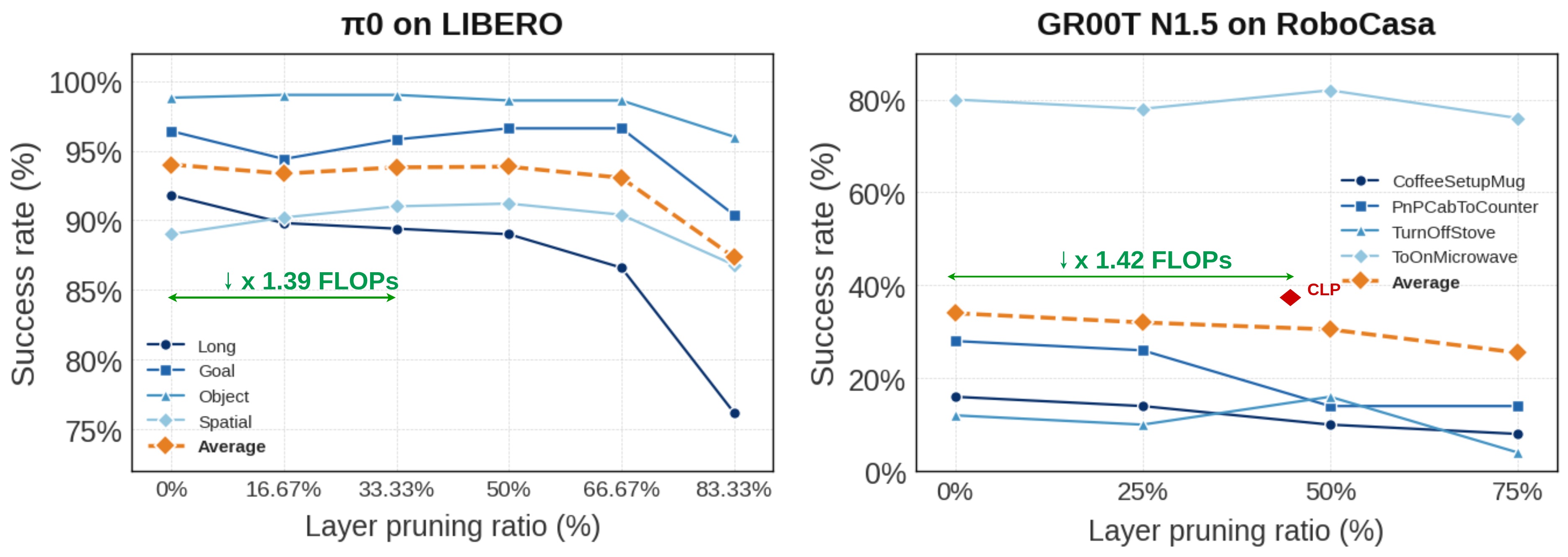
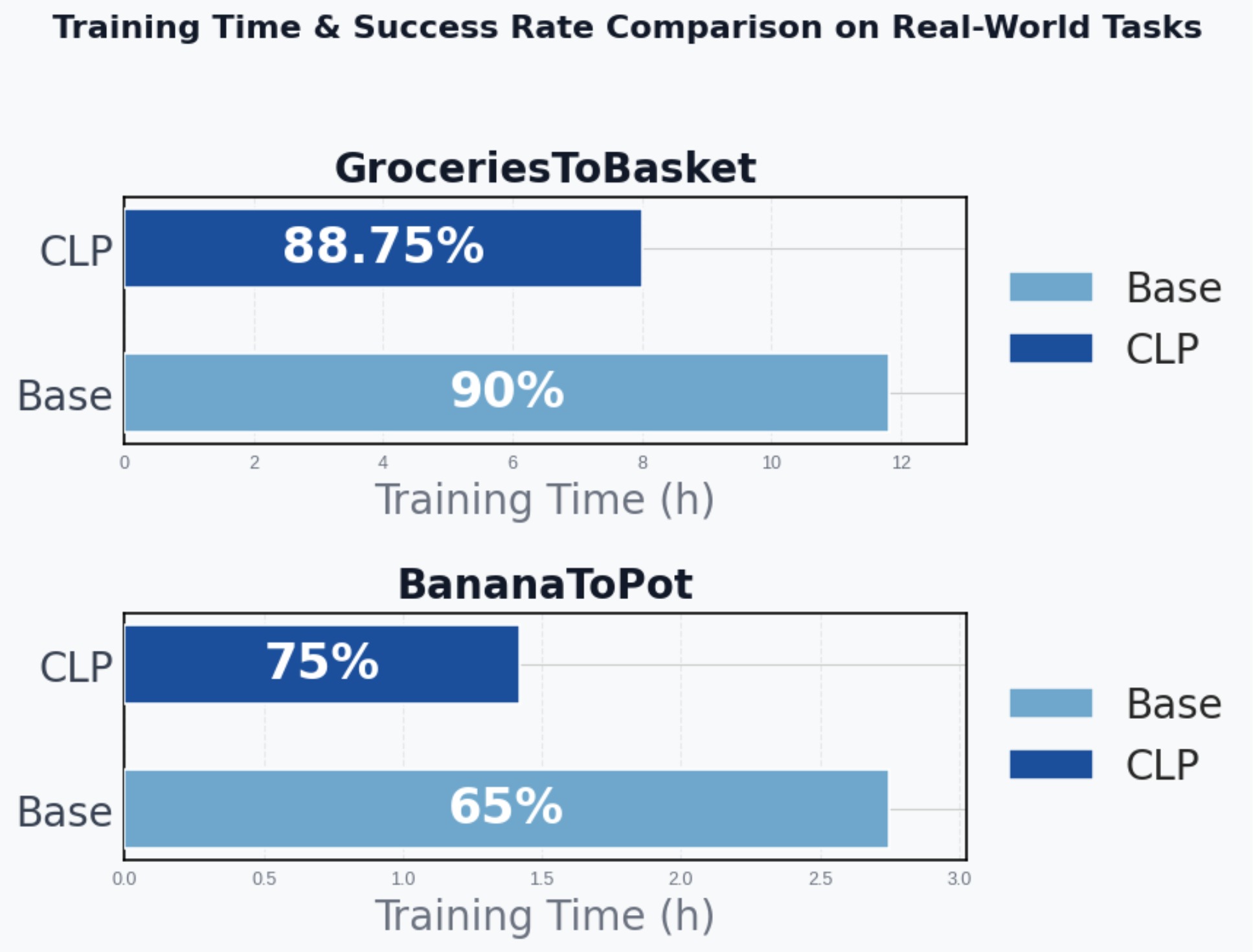
Finetuning Vision-Language-Action Models Requires Fewer Layers Than You Think
1Center for AI Research, VinUniversity
2VinRobotics
3University of Arkansas
4Technical University of Denmark
5Hanoi University of Science and Technology
6KAIST
7Monash University
8Oldenburg University
9DFKI
10University of Stuttgart
11IMPRS-IS
12Stanford University
13Technische Universität Darmstadt
†Project Leads.